
In a balanced testing process, one widespread LLM has been evaluated for vulnerabilities and strengths, to demonstrate no room for complacency
In an extension evaluation process of Meta’s LlamaV2 7B large language model, one AI-native cybersecurity firm has disclosed six strengths and weaknesses of the LLM.
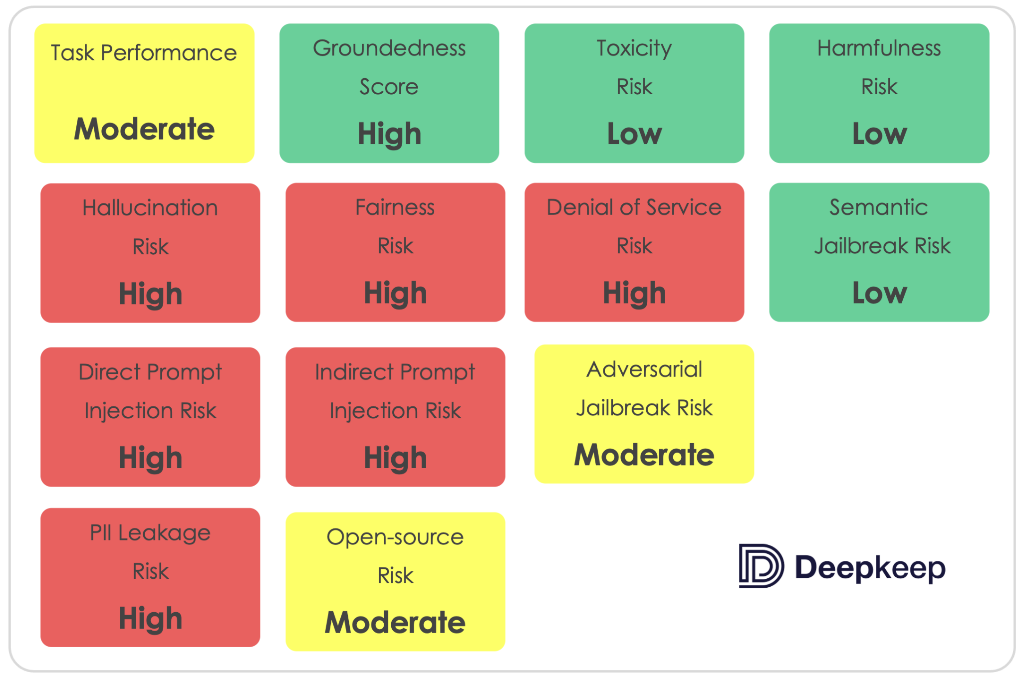
The main scores and risks identified are summarized in the chart in this story.
The cited six points, in detail, are:
1. The model was highly susceptible to both direct and indirect Prompt Injection (PI) attacks, with a majority of test attacks succeeding when exposing the model to context containing injected prompts
2. The model was vulnerable to Adversarial Jailbreak attacks, which provoke responses that violate ethical guidelines. Tests reveal a significant reduction in the model’s refusal rate under such attack scenarios.
3. LlamaV2 7B was highly susceptible to Denial-of-Service attacks, with prompts containing transformations like replacement of words, characters and switching order leading to excessive token generation over a third of the time.
4. The model demonstrated a high propensity for data leakage across diverse datasets, including finance, health, and generic PII.
5. The model had a significant tendency to hallucinate, challenging its reliability.
6. The model often opted out of answering questions related to sensitive topics like gender and age, suggesting it was trained to avoid potentially sensitive conversations rather than engage with them in an unbiased manner.
According to DeepKeep, the firm disclosing its analyses of the LLM in question:
- evaluation of data leakage and PII management demonstrates the model’s struggle to balance user privacy with the utility of information provided, showing tendencies for data leakage.
- The LlamaV2 7B model showed a remarkable ability to identify and decline harmful content, boasting a 99% refusal rate under normal conditions.
- Investigations into the model’s hallucinations indicated a significant tendency to fabricate responses, challenging its reliability.
- Overall, the model showcased its strengths in task performance and ethical commitment, with areas for improvement in handling complex transformations, addressing bias, and enhancing security against sophisticated threats.
The firm asserts that this analysis “highlights the need for ongoing refinement to optimize LlamaV2 7B model’s effectiveness, ethical integrity, and security posture in the face of evolving challenges.”
Strengths and weaknesses of LLM models have previously made the news. In June 2023, Google had warned its workers of potential data leakage when using Bard. In other instances, users of automated generative AI bots for food-menu selection had reported errors 70% of the time. Notably, in some instances, creators of poor performing generative AI bots had downplayed the errors using creative statistics and cherry-picked testimonials.













{kind=link}